



Photo by Markus Spiske on Unsplash
Web Scraping With Node.js and Cheerio 🔥
Create a web scraper using Node.js, Axios, and Cheerio


In this post, I will show you how to create a web scraper using Node.js, Axios, and Cheerio. I use Axios to make an HTTP Request to a website then I use Cheerio to parse the HTML, and extract the data I needed.
Let's get to it. 🚀
Create a Web Scraper with Node.js, Axios, and Cheerio
In this example, I will scrap Hacker News Website (https://news.ycombinator.com/) and extract the news list on it.
First, create a project folder, then npm init or yarn init . You'll get a new package.json file.
Then follow these steps:
Install Axios and Cheerio
yarn add axios cheerio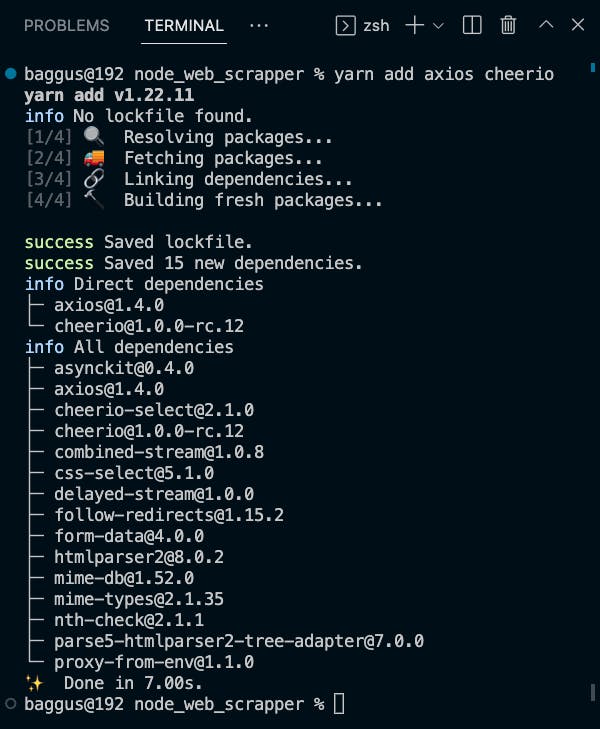
Create a file called
webScrapper.jsImport Axios and Cheerio
const axios = require('axios') const cheerio = require('cheerio')Create a function called
scrape()Make an HTTP call to Hacker News Website. you'll get the string containing the HTML code. To view what the data looks like, I add
console.loginside Axiosthenblock. Don't forget to call the function after that by adding the codescrape()const scrape = () => { axios.get('https://news.ycombinator.com/') .then(({ data: page }) => { console.log(page) }) .catch(error => { console.error(error) }) } scrape()If you want to see the result, run the code with Node.js
node webScrapper.jsYou'll see the result something like this.

That is the same content as from the website.
All right, let's extract the content of the website. I want to get the news title and the URL. So, I inspect the element and find them. As you can see, the news title and URL are available inside
spanwhich hasclasstitleline. So I will get the anchor tag (a), then get the text inside it for the news title and also thehrefattributes for the new URL.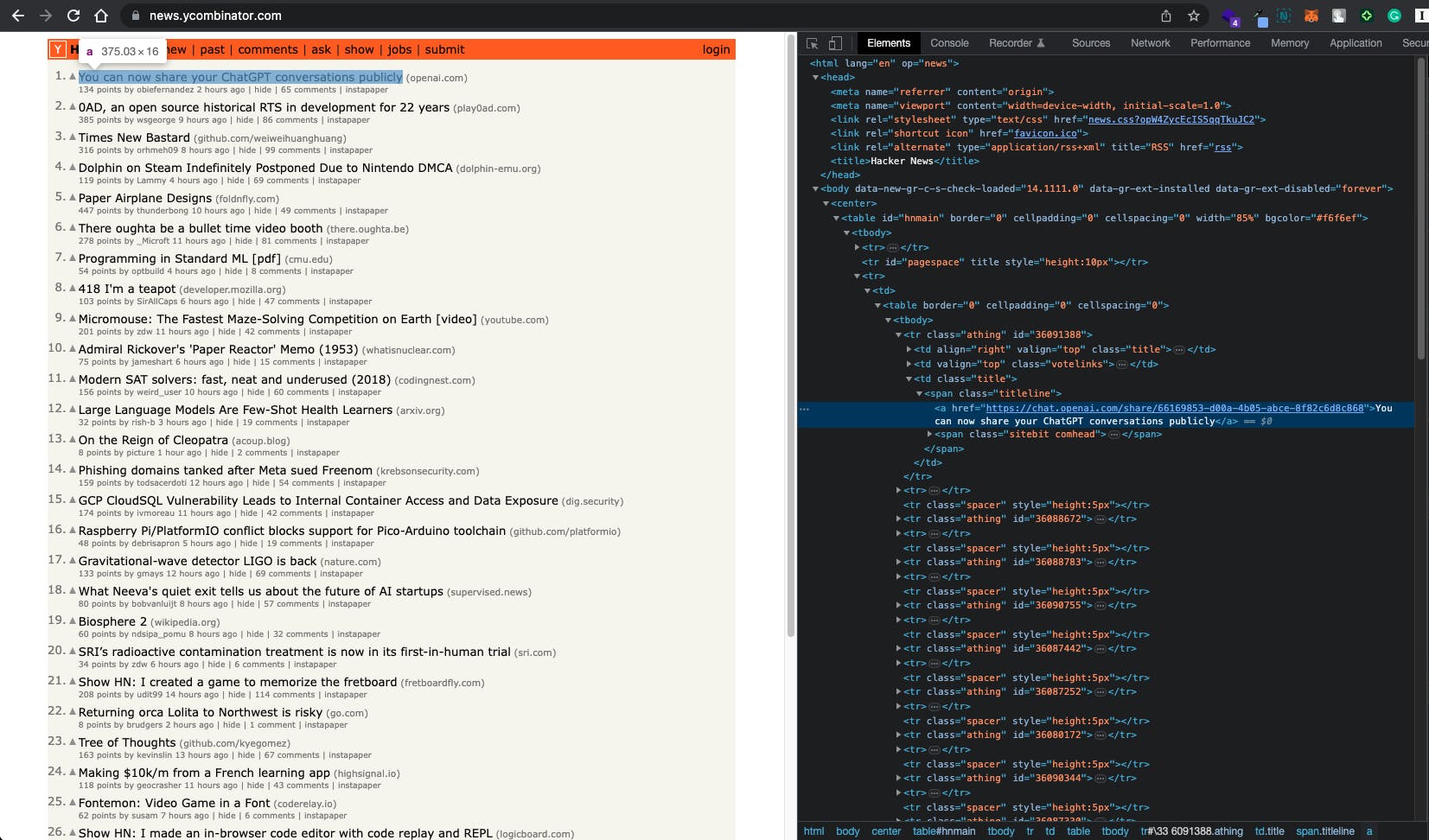
I create a function to extract data from the page
const extractData = (page) => { const $ = cheerio.load(page) const $newsList = $('.titleline > a') const result = [] for (const $news of $newsList) { const title = $news.children[0].data const url = $news.attribs.href result.push({ title, url }) } return result }If you don't understand what the code above does, read this:
cheerio.load= parse string HTML to be Cheerio Object, so you can traverse it$(.titleline > a)= get theanchorelement inside an element that has classtitlelineLoop the
$newsListarray and get the news title and URL, then create an Object and push it toresultarrayreturn the
resultarray
Ok, the extract function is ready. Let's call it inside
scrapfunctionconst scrape = () => { axios.get('https://news.ycombinator.com/') .then(({ data: page }) => { const result = extractData(page) console.log(result) }) .catch(error => { console.error(error) }) }Run the scrapper again to see the result
node webScrapper.jsNow, I have the news list data I wanted as an Array of Object 🔥🔥🔥
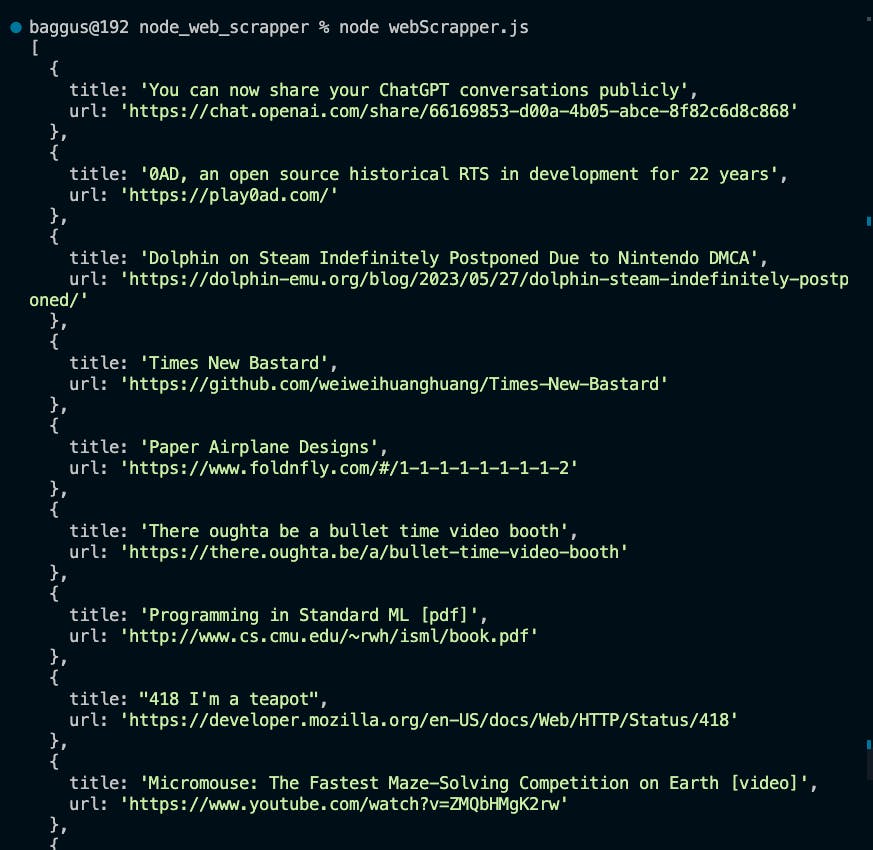
🌟 Here is the full final code 🌟
The result of Web Scraping using Node.js and Cheerio
That's an example of how to create a web scrapper with Node.js, Axios, and Cheerio 😎. Now, when you have the extracted data, you can save it to a CSV file, Google Spreadsheet, or a database, or post it to another place you want. If you want to see how to do it, write a comment below and I will write an article about it.
Please do web scrapping wisely. Thank you. 😉